DFIR approach in Velociraptor
Khác biệt giữa cách tiệp cận của Velo với DFIR truyền thống
Bài viết so sánh cách tiếp cận của Velociraptor (Velo) với cách tiếp cận DFIR truyền thống. Velo chủ yếu phân tích ở phía Client, giúp giảm tải cho server và tăng tốc độ xử lý. Ngoài ra, Velo tập trung vào các dữ liệu có giá trị cho việc DFIR cụ thể, có tính năng collect cho phép thu thập dữ liệu có chủ đích rồi upload lên server để phục vụ mục đích điều tra. Velo cũng có tính năng tích hợp các parser framework như Grok và Sqlite. VQL của Velo được thiết kế để tự động hóa nhiều công việc DFIR thường gặp.
Traditional approach
Quá trình điều tra số thông thường:
- Trích xuất thông tin
- thu thập raw data từ endpoint
- MFT, Evtx,…
- các data có giá trị phục vụ cho việc Forensics
- nén
- tar, zip, vhdx,…
- giảm kích thước
- thu thập raw data từ endpoint
- Upload/copy đến server phân tích
- cloud upload
- external drive → copy
- Phân tích data trên server (timesketch, elastic, opensearch, etc.)
- standalone tools
- timeline
- etc
Velociraptor approach
parse và analyze data ở trên chính máy endpoint
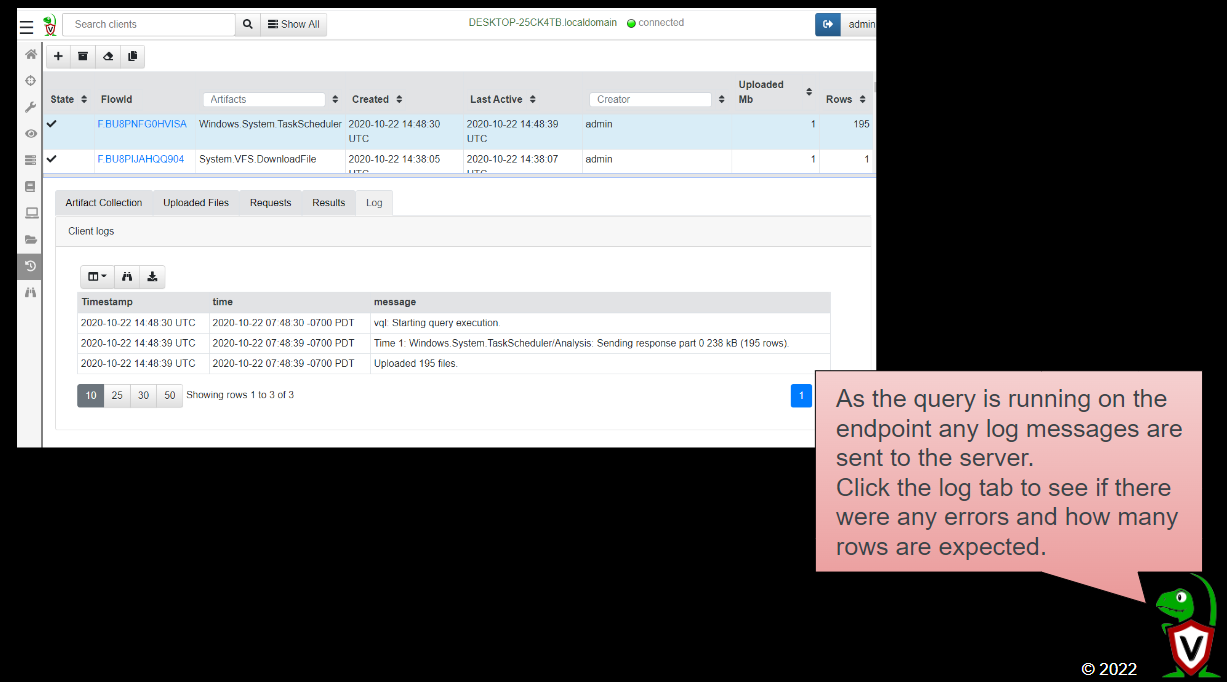
As the query is running on the endpoint any log messages are sent to the server. Click the log tab to see if there were any errors and how many rows are expected.
collect có chủ đích các artifact
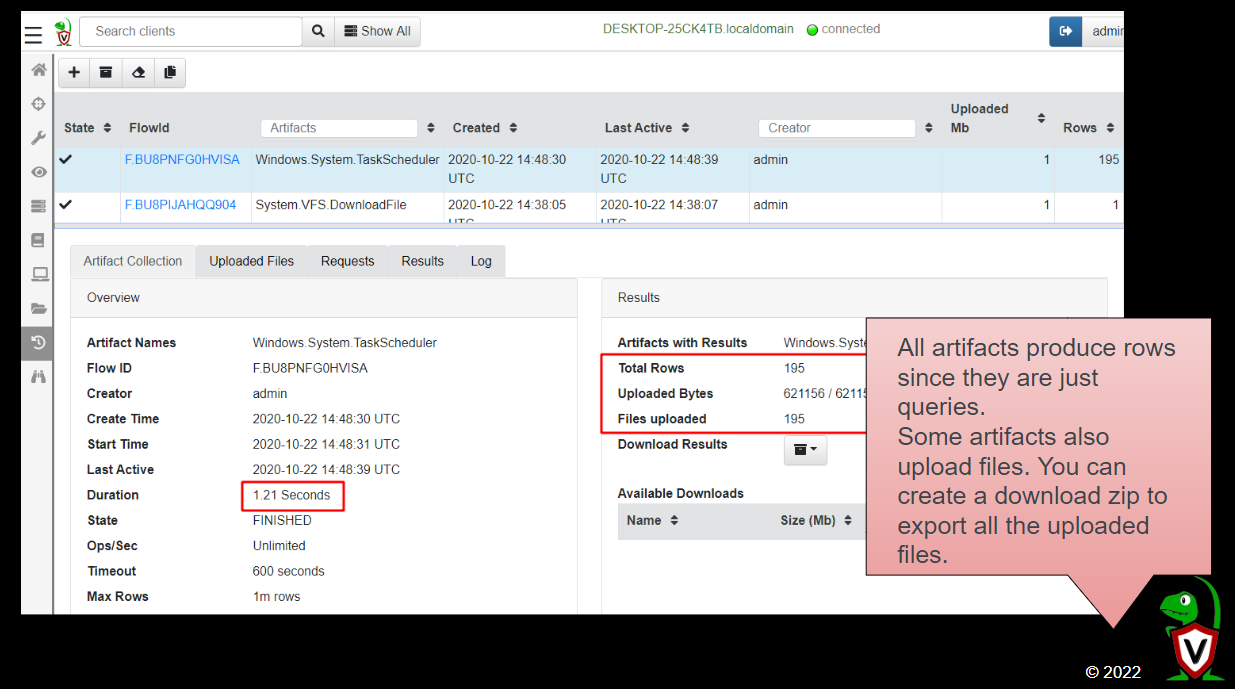
All artifacts produce rows since they are just queries. Some artifacts also upload files. You can create a download zip to export all the uploaded files.
có thể link/scale các collection
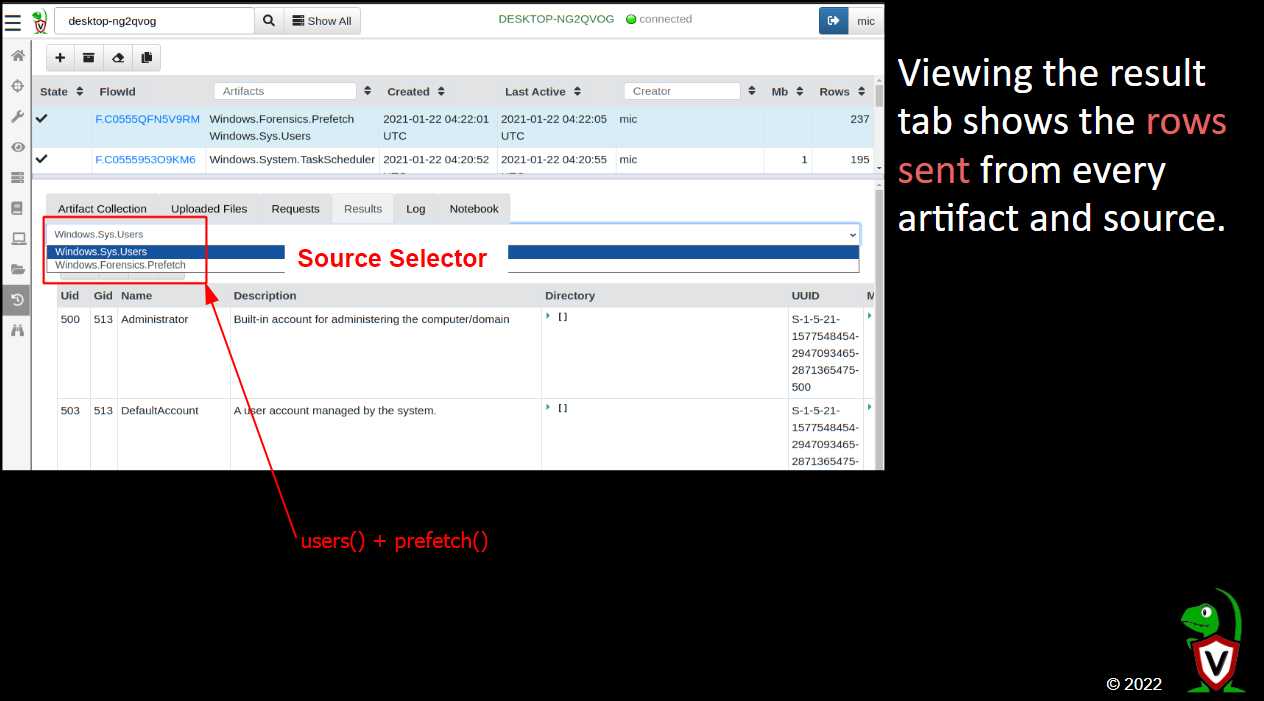
vì sử dụng ngôn ngữ query nên dễ dàng, linh hoạt trong việc tạo các analysis khác nhau
- VQL
- .yaml file với các trường metadata xung quanh truy vấn
- dễ dàng chia sẻ trong cộng đồng
- dễ dàng hiểu mà thậm chí k cần biết VQL
Visualize:
Ví dụ 1 case thực tế

Difference

1 thế mạnh khác của VQL là có thể tích hợp các parser framework
- Grok: is a way of applying regular expressions to extract structured information from log files.
- Used by many log forwarding platforms such as Elastic
- Grok expressions are well published
- Can be incorporated into VQL.
- Sqlite: parse database SQL
- etc
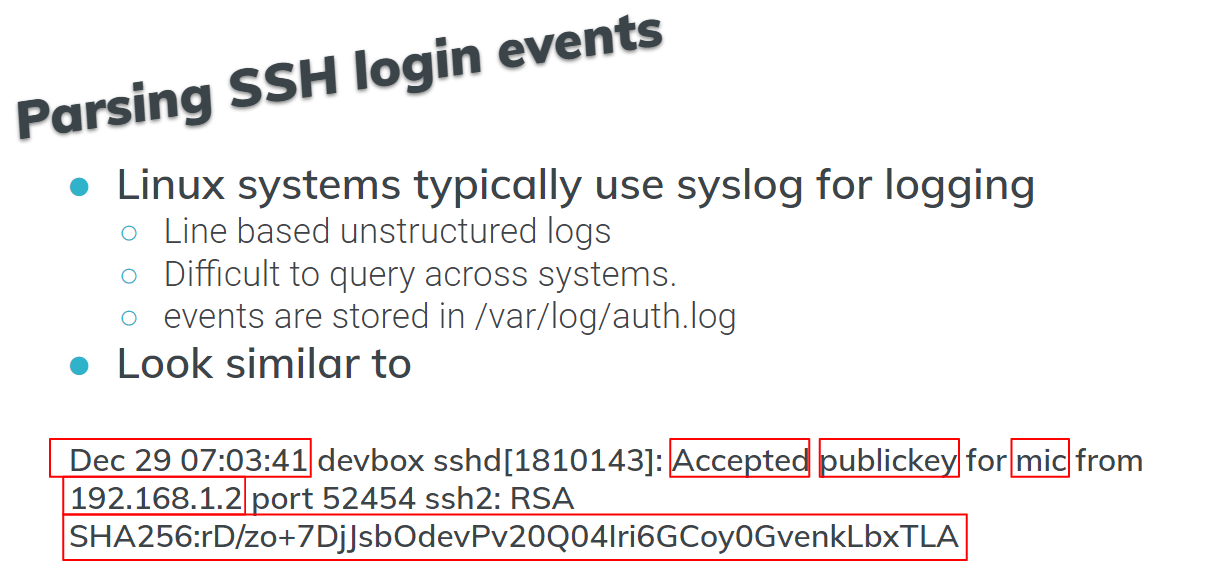
Ví dụ trong việc parse SSH log sử dụng grok

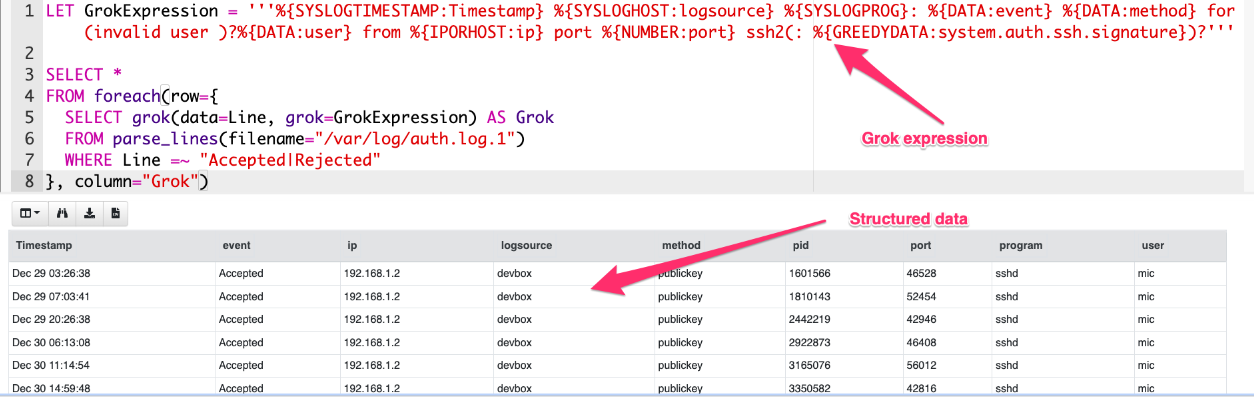
Sumary
- Design: Thay vì thực hiện phân tích chủ yếu ở server như cách DFIR truyền thống, Velo chủ yếu phân tích ở phía Client (ở server chỉ là post-process)
- Lợi: share tải cho clients tự xử lý thay vì bắt 1 server đảm nhiệm chức năng xử lý 1 lượng lớn dữ liệu
- server phải đủ mạnh → cost phần cứng cao
- trong khi client đã có sẵn phần cứng, chỉ cần xử lý 1 lượng thông tin nhỏ (hơn rất nhiều so với khối lượng trên server - nếu tiếp cận theo cách truyền thống)
- thời gian xử lý trên server sẽ lâu hơn (rất) nhiều so với chạy đồng thời trên các endpoint rồi gửi về server
- Hại: có thể gây cao tải cho client khi trực tiếp xử lý, phân tích artifact
- Velo đã tính đến việc này ngay từ khi thiết kế ban đầu, việc của threat hunter là limit CPU usage/opsec/time/… cho mỗi lần hunting
Client memory and CPU usage is controlled via throttling and active cancellations.
- Velo đã tính đến việc này ngay từ khi thiết kế ban đầu, việc của threat hunter là limit CPU usage/opsec/time/… cho mỗi lần hunting
- Lợi: share tải cho clients tự xử lý thay vì bắt 1 server đảm nhiệm chức năng xử lý 1 lượng lớn dữ liệu
- Approach: Thay vì Thu thập khối lượng lớn dữ liệu như cách tiếp cận DFIR truyền thống, Velo tập trung vào các dữ liệu có giá trị cho việc DFIR cụ thể
Velo cũng có tính năng collect cho phép thu thập dữ liệu (file) có chủ đích rồi upload lên server để phục vụ mục đích điều tra
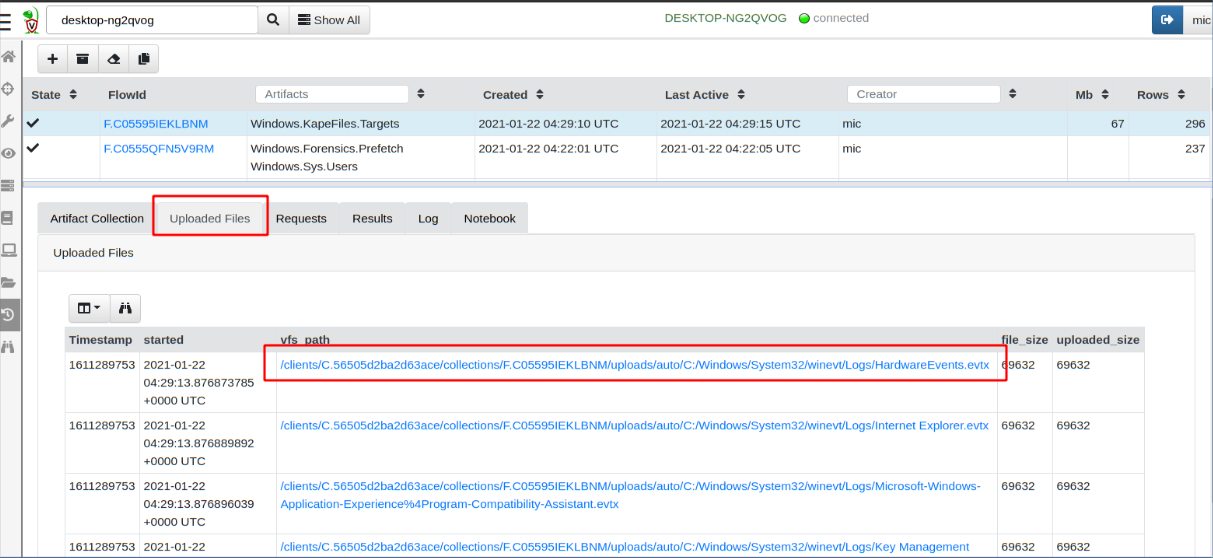
Khi hunt/run artifact → option
parameterscài đặt upload fileServer cũng được handle, **optimized** để xử lý vấn đề tốc độ và khả năng mở rộng
- Concurrency để đảm bảo tính ổn định
- Bandwidth limit để đảm bảo băng thông mạng ổn định
DFIR in VELO
The goal of VQL is to automate as much **of the **routine DFIR work as possible
refer: SANS 2022 summit